張老師您好:
請教您為什麼在執行一階CFA分析時,卡方值為0,而且看不到任何模型配適度呢?哪裡弄錯了?如何解決這個問題?
張偉豪老師解答 :
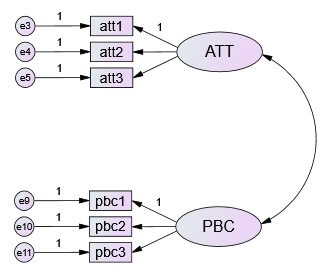
在CFA的分析中,一個潛在構面如果只有搭配3個題目,稱為恰好辨識。
這是CFA分析中的必要條件之一。
SEM模型辨識可分成三種類型:
1.過度辨識(over identification)
2.恰好辨識(just identification)
3.不足辨識(under identification)
辨識(Identification)又譯為正定。亦即指模型是否可以被分析的條件,其條件是否符合是由自由度(DF)-估計參數(P)是否大於0來決定。DF的計算是V(V+1)/2,V表示模型中的觀察變數。
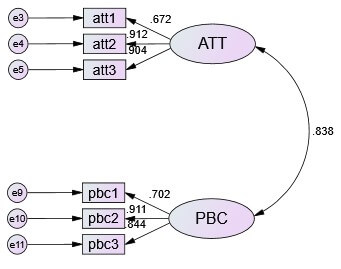
1.恰好辨識(DF-P=0)的意義是資料所提供的訊息恰好等於模型所估計的參數,因此參數估計只會有唯一值,所以模型配適度指標只會出現卡方值為0(表示沒有任何誤差),GFI=1的結果。以一個潛在構面,3個觀察變數為例,DF=3×4/2=6,圖上顯示估計6個參數(打勾的部分)
2.過度辨識表示模型DF-P>0,此為CFA或SEM所希望的方式,如下圖,DF=4×5/2=10,圖上顯示估計8個參數(打勾的部分),因此10-8=2,所以剩兩個自由度,因此CFA為過度辨識。
3.不足辨識為DF-P<0,此時模型將無法分析,如圖所示DF=2×3/2=3,而目前的估計參數有4個(打勾的部分),因此模型無法分析。
一般在CFA分析中,恰好辨識是基本要求,所以一般情形下,每個潛在構面最好是有3個(含)以上的觀察變數是比較理想。但有些讀者仍會發現,有些研究在構面上只設2個題目,但仍能分析,這是怎麼一回事?這個問題留待之後再回答。
結論:結構方程模型(SEM)中的CFA只有3個題目叫做恰好辨識 。
只能判別標準化係數。
如果有超過0.7以上且未超過0.95。
然後殘差均為正值且顯著就過關。
(可以參考SEM論文寫作不求人一書的138頁)