張老師您好:
LISREL的八大矩陣為何?
張偉豪老師解答:
LISREL為SEM軟體中的第一品牌,歷史最悠久,
它利用PRELIS語法作資料處理,
SIMPLIS語法處理較簡單的模型分析功能,
LISREL語法處理較複雜的結構方程分析,
在LISREL語法中要用到矩陣的觀念來寫程式,因此要對各種矩陣有相當的認識,否則語法非常容易寫錯,要詳細了解LISREL語法操作,請參考LIEREL操作手冊,以下簡單介紹LISREL的八大矩陣(1~8),9~12在有平均數估計時才會出現
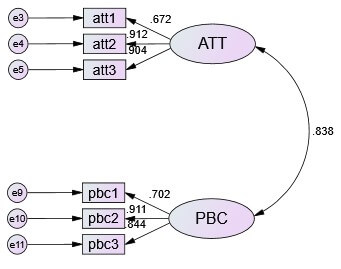
1.Lambda X Matrix:這是設定從外生潛在變項(自變數)到它的觀察變項之間的迴歸路徑,一般會在其中的一條路徑迴歸係數設 “1″
2.Lambda Y Matrix:這是設定從內生生潛在變項(應變數)到它的觀察變項之間的迴歸路徑,一般會在其中的一條路徑迴歸係數設 “1″
3.Theta Delta Matrix:指的是外生觀察變項的誤差項(不可解釋變異).如果有n個題目,就會產生n*n的矩陣.
4.Theta Epsilon Matrix:指的是內生觀察變項的誤差項(不可解釋變異).如果有m個題目,就會產生m*m的矩陣.
5.Phi Matrix:外生潛在變項的矩陣,若對角線為1,表示潛在變數的變異數要被估計(標準實務的作法),若對角線不為1,顯示為潛在變數之間的皮爾森相關.
6.Gamma Matrix:此矩陣為模型的核心,表示外生潛在變數到內生潛在變數的路徑關係.
7.Beta Martix:表示內生潛在變數到內生潛在變數的路徑關係.
8.Psi Matrix:內生潛在變數殘差矩陣,若只有一個內生潛在變數,則矩陣只有一個 “1″
9.Kappa Matrix, KA:在模型中有交互作用的時候使用, 1表估計潛在變數的平均數
10.Alpha Matrix:在模型中有交互作用的時候使用,主要是估計外生潛在變項與內生潛在變項其迴歸值的截距
11.Tau-X Matrix:在模型中有交互作用的時候使用,外生潛在變項到其指標迴歸值的截距.
12.Tau-Y Matrix:在模型中有交互作用的時候使用,內生潛在變項到其指標迴歸值的截距.